Tesseract OCR Software GUI
Welcome to the official home page for the (a9t9) Free OCR for Windows Desktop tool. As the name suggests, it extracts text from image files and PDF items. It uses the open-source Tesseract OCR engine from HP/Google for OCR processing.
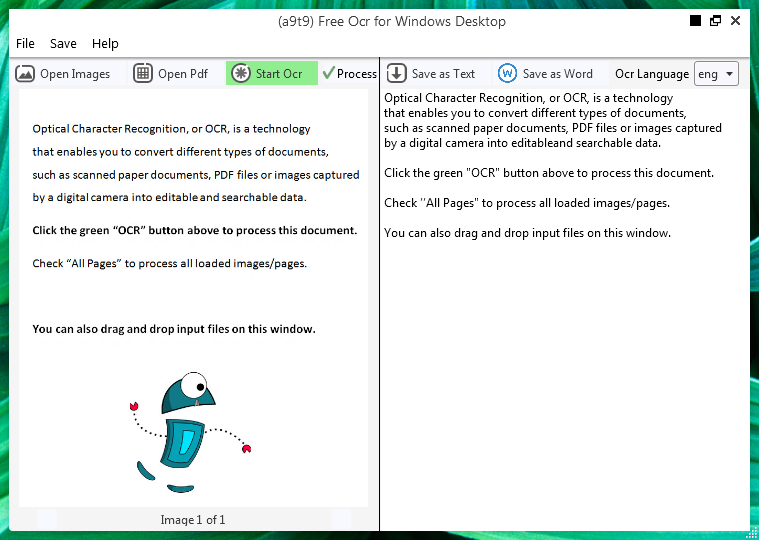
Why use (a9t9) Free OCR for Windows Desktop?
- The application is simple to install/uninstall, and very easy to use
- Free to use
- 100% adware and spyware free
- Uses the well-known Tesseract OCR engine (so essentially it is a modern Tesseract GUI)
- You can improve and customize it - it is open source (GPL)
If you have not done it yet, download the installer here:
- Download Free OCR for Windows Desktop (~30MB, runs on Win 7 and higher)
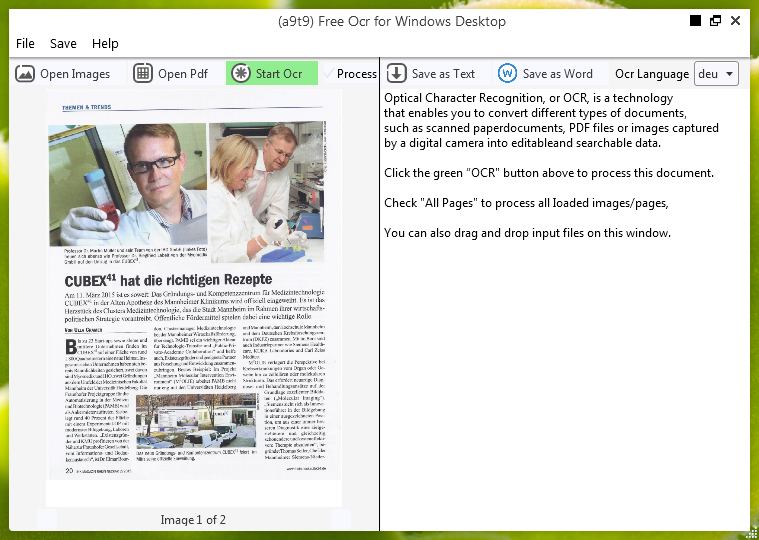
How to get started:
You can open an image or PDF file. The content of the source file will be displayed in the left window. If your document has more than one page, or if you opened multi-page documents, use the arrows at the bottom to navigate between them,
You start the OCR by clicking the green Start Ocr, and you will see the result in the right window. Output text can be saved as a text file or Word document.
Unfortunately the conversion quality is not so great. Behind the scene it uses the Tesseract open-source OCR engine. Its quality varies from language to language - so go ahead and test if it is sufficient for your needs.
Tips for better recognition results:
Tesseract’s output will be very poor quality if the input images are not preprocessed to suit it:
- Images (especially screenshots) must be scaled up such that the text height is at least 20 pixels.
- Any rotation or skew must be corrected or no text will be recognized,
- Dark borders must be manually removed, or they will be misinterpreted as characters.
Still need better text recognition results? Then try these new alternatives:
1. Online OCR - our free web-based OCR app.
2. OCR API - our free web API**, includes OCR command line examples with cURL.
3. Windows 8 OCR software - our free, open-source (GPL) Windows Store OCR app.
Both new services use a different OCR component and have much better text recognition rates than the Tesseract-based OCR desktop software on this page.
For software developers and geeks:
The (a9t9) Free OCR for Windows Desktop tool is a graphical user interface front-end (GUI) for the Tesseract engine. It is written in C#/WPF and the full source code is available as ready-to-compile Microsoft Visual Studio 2013 project on GitHub under the GPL V2 open source license. Feedback of all kind is welcome, especially ideas on how to improve the OCR quality. In the Best OCR Software review on this blog the mediocre OCR performance of Tesseract was on of the Five OCR surprises of this test.
How to add more languages
One of the key advantages of the Tessearct engine is the wide variety of supported OCR languages - it even includes Esperanto! The (a9t9) Free OCR for Windows Desktop installer includes English (ENG), Spanish (SPA) and German (GER). To add more languages just follow these three steps:
- Download the language file you need from Google code, for example Chinese (Traditional).
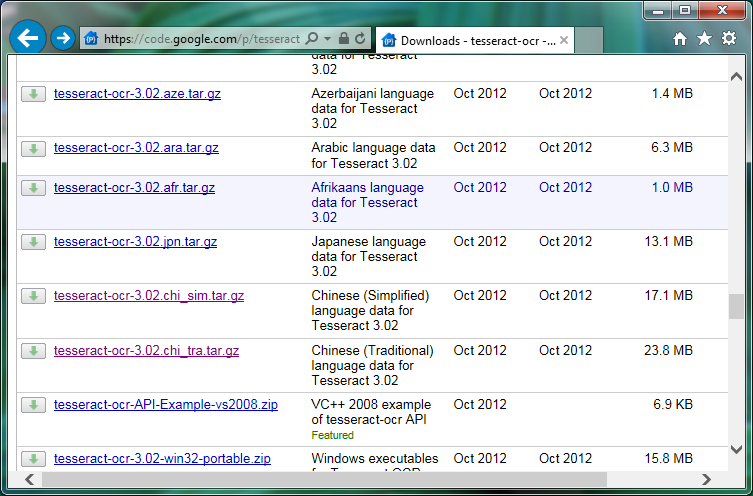
- Un”zip” the download (first the .gz file, and then the .tar file inside). If you have no software to manage compressed archives yet, get free 7zip tool. It is a great choice.
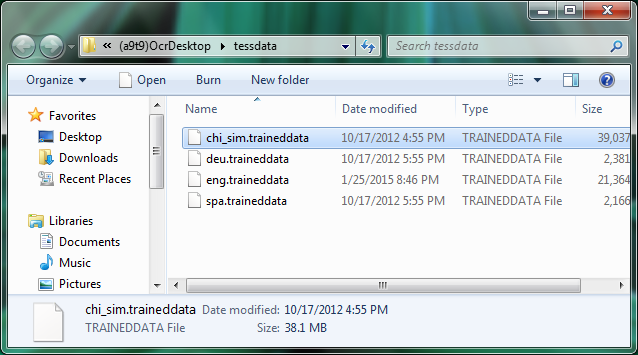
- Copy the files into the tessdata language folder on your PC. You find that folder easily by opening it from inside the application. In the menu of the OCR software go to the Help > Open Language Folder - and a new Explorer window opens.
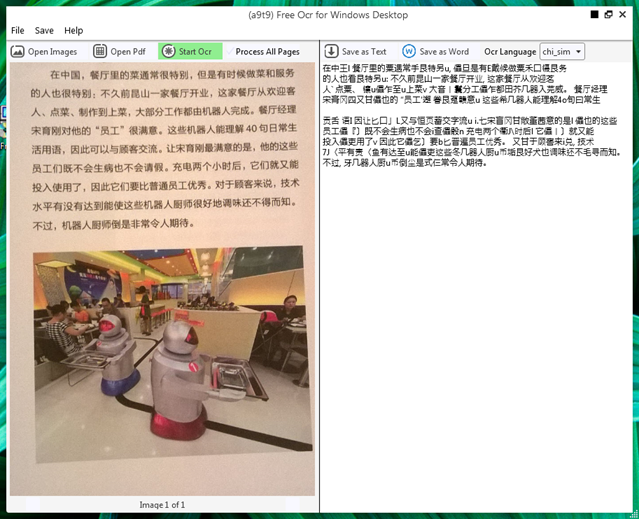
The Tesseract OCR results are mediocre, but still better than transcribing the text yourself
Now start the software again and the new language appears in the OCR language selection drop down as abbreviated code, e. g. ENG for English, SPA for Spanish, GER for German, POR for Portugese , CHI_TRA for traditional Chinese character support or CHI_SIM for simplified Chinese character support.