Kid, how have you grown? The amazing progress of computer vision in recent years.
You probably know that Computers can find images in other images, or can detect faces or lane markers and road signs. But did you know that (only) since a few years computers already know what they are actually looking at?

The recently completed ImageNet Large Scale Visual Recognition Challenge 2014 shows some amazing progress. In boring terms, the overall goal of the ILSVRC 2014 contest is to estimate the content of photographs. But what we here actually having here is some kind of world championship for computer vision. “Robots” (or more exactly: their algorithms) compete against each other to find out who “sees” best.
The contest has three categories, with increasing difficulty:
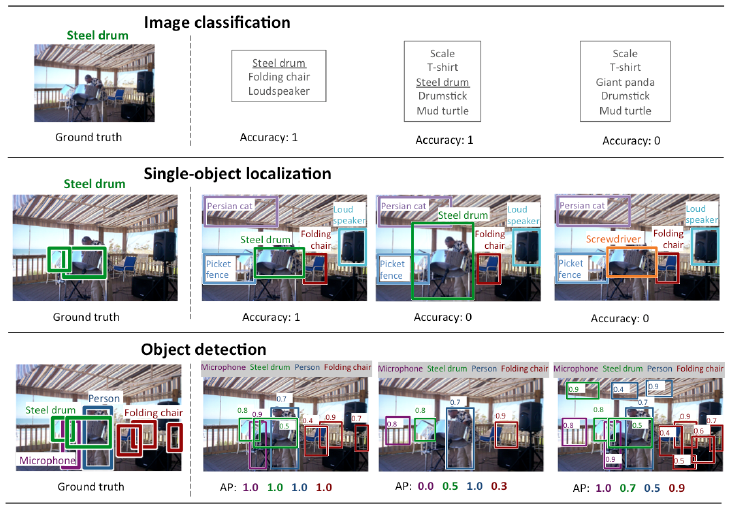
1. Image classification
Given an image, tell me what you see on it. The image has one major item on it, e. g. a zucchini. For each image, robots produce a list of objects (they think are) present in the image. The quality of a labeling is evaluated based on the label that best matches the original (human created) label for the image.
2. Object level annotation: Single Object localization
Same as Image classification, with the additional requirement that the location of the object must also be determined correctly via a bounding box.
3. Object level annotation:Object detection
Same as Single Object localization, but with multiple object categories in the image.
In other words: Tell me all that you see on the image and on what position. Also, an image can have multiple occurrences.
The dataset
Constructing a dataset with over 1000 categories and more than a million annotated images for this contest in a challenge of its own, see From Abacus to Zucchini: What Robots Learn in Kindergarten.
For this post, lets focus on image classification.
The improvements and current status
The contest runs since 2010 and we have seen an amazing improvement over the years. The the strong drop in classification errors during ILSVRC2012 was a turning point for large-scale object recognition. It was when large-scale deep neural networks entered the scene.
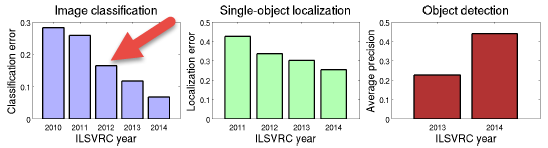
So where are we now? As often, a picture is worth a thousand words - so look at this:

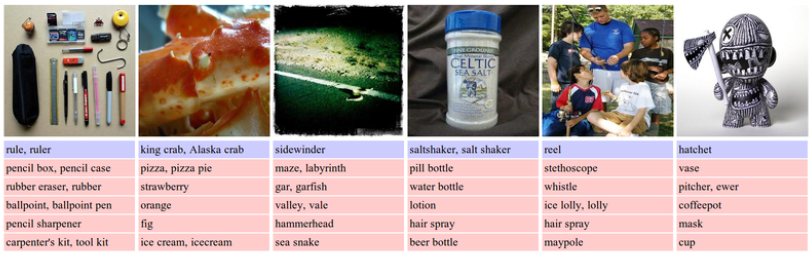
For image classification, it turns out that mammals like “red fox” and animals with distinctive structures like “stingray” have a 100% recognition rate! And that includes obscure dog breeds like “schipperke”. The hardest classes in the image classification task include small objects,such as “hook” and “water bottle”. And, not surprisingly, highly varied scenes such as “restaurant.”
In general, robots still struggle with images that contain multiple objects, images of extreme closeups and uncharacteristic views, images with filters/distortions, images that significantly benefit from the ability to read text, images that contain very small and thin objects and images with abstract representations.
Humans, on the other hand, have their own set of challenges:
How about human vision?
In the image classification contest two humans competed against the robots. Just like the robots, the humans were trained with the test images and had then to compete in correctly labeling the contest image, using a web interface.
The result:
1. Labeling errors, humans: 5.1%
2. Labeling error, best robot: 6.7%
So humans won! - but only with a small margin. If the progress continues it will not before long that computer vision gets its Deep Fritz moment, and robots overtake humans.

So to come back to xckd: “…and check whether the image is of bird”? That is a solved problem - including the species. But also keep in mind that the ImageNet contest images are more than 1 Terabyte of data to process (~1 million images!). So it will still take some time before your smartphone can do the same tricks* (Deleted this ambiguous last sentence as per the great comment below. I had the limited processing power of smart phones in mind when I wrote this,… see my upcoming reviews of existing smartphone apps that do local, on device image recognition [link here once published]).
Credits: All images (except xkcd) and the inspiration for this post from the great overview paper ImageNet Large Scale Visual Recognition Challenge by Olga Russakovsky et al.