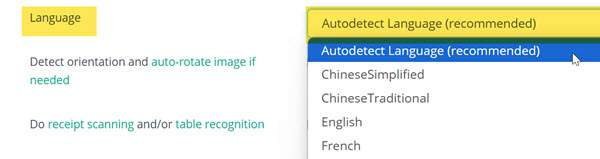
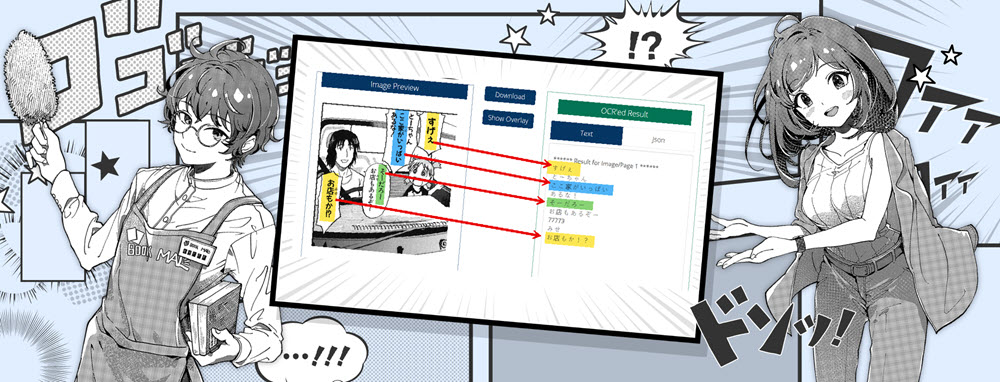
Our OCR Engine 3 features advanced handwriting recognition capable of reading over 200 new OCR languages - including Arabic, Chinese, Japanese, and Korean.
You might tried OCR before — Adobe, Google, scanner apps and our very own OCR engines 1 and 2. Great for printed text, but not useable for handwriting. But retyping by hand takes hours, and without converting the handwritten documents to text you can not search or use them.