The Best Online OCR Software for Converting Images to Text

Update May 1, 2015: (a9t9) launched its very own free and open-source Online OCR service - try it out and let us know how it compares.
What is the best free optical character recognition (OCR) service to convert (text in) images to plain, editable text? This review compares the recognition accuracy of free and commercial cloud OCR offerings. No-name OCR beats Google Docs OCR is just one of the surprising test results.
Usability, speed, formatting, non-English language support are not rated. This market overview is all about finding the best online service to convert images to plain text.
Six documents that are gradually more difficult to recognize serve as OCR benchmark: A screenshot, two scans, a mobile phone camera picture and, as highlight, text of an XKCD comic and readings from the image of a gas meter. The test results were not what you would expect. Read more about the five OCR surprises.
OCR Test 1: Recognize text in screenshot
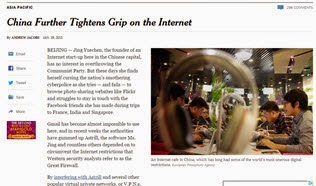
You find the original input images by clicking on the preview image in the table headers - or see the reference section below.
The first four tests use the New York times article as input. In the first round, the OCR input is a screenshot of the article – the image quality can not get better. And as the newspager name suggests the font is straight forward -Times New Roman.
Test 1: Screenshot OCR 
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abbyy Cloud SDK | 100% | Internet start-up here |
| Google Docs OCR | 100% | Internet start-up here |
| OnlineOCR | Good | Internet start-up here |
| i2 OCR | Good | Internet start-up here |
| FreeOnlineOCR | Good | Internet start-up here |
| Tesseract Online | Fail | Intemel SK-3!’l—.\p hereiii |
| AntiMatter.Js | Fail | IIllelnel _hl _p he_P |
The purpose this first easy task was to wheat out any essentially not working online OCR services. Two services flunked this test: Orcad.js and – Tesseract.
What? Tesseract???
Surprise #1: Yes, Tesseract flunked this test. That is a huge surprise. According to Google “Tesseract is probably the most accurate open source OCR engine available.” This makes me feel a bit like an elementary school teacher who has to give bad grades to the son of the major - so I first blamed the online version of Tesseract (at CustomOCR) that I am using. I doubled checked the result with PDF OCR X, a Windows/Mac tool that wraps the Tesseract-OCR engine. The result is not as bad as in the Tesseract online demo, but still poor. If someone can explain the bad result, I would be very interested to hear!
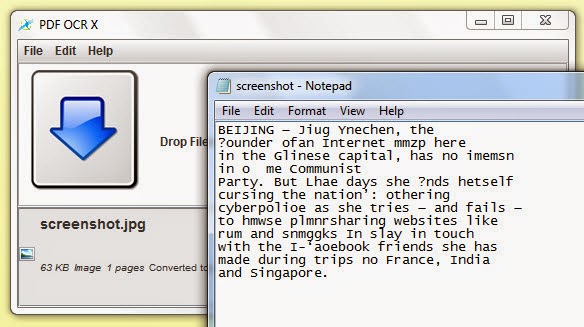
with PDF OCR X, a desktop OCR software that uses the Tesseract engine.
OCR Test 2: High-Quality Scan
Test setup: A printout of the NY Times article was scanned at a resolution of 100dpi. As some services do not take PDF format as input, the JPEG (JPG extension) format is used as the lowest common denominator in all tests.
Test 2: High-quality Scan OCR 
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abbyy Cloud SDK | 100% | BEIJING — Jing Yuechen, |
| Google Docs OCR | Good | BEIJINGJing Yuechen, |
| OnlineOCR | 100% | BEIJING — Jing Yuechen, the |
| i2 OCR | Good | BEIJING — J ing Yuechen, |
| FreeOnlineOCR | Good | BEIJING - Jing Yuechen~ |
| Tesseract Online | Good | BEIJING — Jing Yuechen, |
No big surprises here, OCR on high-quality scans worked ok with all services.
OCR Test 3: Low -Quality Scan
Test setup: The printout was scanned at a resolution of 75 dpi, printed out again and scanned a second time at 75dpi. The result is a low quality scan. Nevertheless the image still easily readable for humans.
Test 3: Low-quality Scan OCR 
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abbyy Cloud SDK | Good | BEIJING — Jing Yucchen, |
| Google Docs OCR | Poor | EEN; – ing Yucchen, , |
| OnlineOCR | Good | BEIJING - ding Yuechen, |
| i2 OCR | Poor | BI-‘.IJtNG — Jing Yucchcn, |
| FreeOnlineOCR | Fail | Bta t0 mt 21 the e |
| Tesseract Online | Fail | BEIJING — -1 ing Yuodzcn, |
Surprise #2: Google OCR did worse than the “noname” OnlineOcr service (and Abbyy)! My clear expectation at the start of this market research was that Google’s OCR service will set the gold standard. After all, Google is the company that builds self-driving cars and won the ImageNet Visual Recognition Challenge last year.
OCR Test 4: Smartphone Camera
Your camera as a document scanner? That is possible in 2015. For this test the meanwhile well-known NY times article was printed out, and then folded/unfolded. The result is a creased and slightly wrinkled printout. This makes the task more realistic in a reproducible way. Usually you are not in a photo studio when archiving your creased receipts or coffee-stained invoices.
{kind=link}
Test 4: Mobile Phone Image OCR 
| OCR Service | Result | Output (Excerpt) | ||
|---|---|---|---|---|
| Abbyy Cloud SDK | Poor | rely heavily on leu-fetierea | ||
| Google Docs OCR | Poor | rely muneinterne - anorameror | ||
| OnlineOCR | Poor | rely heavily on lass-fettereir | ||
| i2 OCR | Poor | rely hcavilyon less-fctt | ||
| FreeOnlineOCR | Fail | (no output) | ||
| Tesseract Online | Fail | 7- \5g@ | ff‘<. - nu-lain |
None of the OCR engines did well in this benchmark, plenty of room for improvement. No longer a surprise: Google OCR did again worse then the free OnlineOCR service and Abbyy’s commercial OCR solution.
OCR Test 5: Recognize an XKCD comic (tricky font)
XKCD comics are fun – and not difficult to read for humans (just sometimes difficult to understand?). Can robots read them better?
Test 5: Read a XKCD comic 
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abbyy Cloud SDK | Fail | nrs udr d hcu 111 oaismiY |
| Google Docs OCR | Fail | ITS UERD HOUTM (DNSIANTY |
| OnlineOCR | Poor | 115 WEIRD HOW rM CONSTANTLY |
| i2 OCR | Fail | fT5UElRD HOlJD’1CON$I’PNlLY |
| FreeOnlineOCR | Fail | (no output) |
| Tesseract Online | Fail | TFSUEIKP HOUI‘r’l0)NSWlTLY |
Surprise #4: While OnlineOCR received a passing grade with its “poor” result, all other services failed completely. Amazing! In other words: XKCD speech bubbles are so difficult to decode, they could be used as CAPTCHAs :)
OCR Test 6: Recognize a number in an image
This is not your typical OCR task. Number recognition inside an image is not easy. After all, Google uses house numbers in its reCAPTCHA service.
OCR Test 6 was easier: The image contained the number in horizontal orientation and with no disturbing background.
OCR number recognition has many applications: There are billions of of analog and digital gauges in houses and industrial settings that have no API or user interface and are not easily replaced. Reading them via taking an image and running OCR on it is often the an economical solution. The input image number used in this test is a high-quality mobile phone image of a gas meter. The image was cropped down so it just contains the reading.
Test 6: Number OCR 
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abbyy Cloud SDK | Good | 0491024,3 |
| Google Docs OCR | Fail | (no output) |
| OnlineOCR | Fail | 0 6 4 0 |
| i2 OCR | Fail | 01} § 7 6,2 F. |
| FreeOnlineOCR | Fail | (no output) |
| Tesseract Online | Fail | f11l§7fi,2Z?3§- |
Surprise #5: Every service completely flunked this test except Abbyy’s FineReader engine, who delivered a good result.

Summary & Online OCR Converter Ranking:
The following tables summarizes the results and ranks the services.
| Ranking | Score | Screen | Scan1 | Scan2 | Mobile | XKCD | Number |
|---|---|---|---|---|---|---|---|
| Abbyy Cloud SDK | 10 | ++ | ++ | + | 0 | - | + |
| OnlineOCR | 9 | ++ | ++ | + | 0 | 0 | - |
| Google Docs | 7 | ++ | + | 0 | 0 | - | - |
| i2OCR | 6 | + | + | 0 | 0 | - | - |
| FreeOnlineOCR | 4 | + | + | - | - | - | - |
| Tesseract | 2 | - | + | - | - | - | - |
| Ocrad.JS | 0 | - | - | - | - | - | - |
The clear winner is Abbyy’s commercial service. The “no-name” OnlineOCR website ranks #2, before Google OCR, which comes in only at the third place. i2OCR works also fine (albeit slow). All other services can not be recommended.
References:
Reviewed online OCR services:
OCR Test images:
- Screenshot
- High-quality scan
- Low-quality scan
- Smartphone image
- XKCD speech bubble
- Gas-meter reading
- All test images are available on GitHub: OCR Benchmark
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}