
Improved Number OCR and Special Character OCR with OCR Engine2
We launched a new OCR Engine that brings improved numeric and alphanumeric OCR and special character OCR.
We implemented the second OCR Engine to give you access to a second OCR algorithm. It is better than the default engine (now called “engine1”) in many cases for Latin character languages (e. g. English OCR, French OCR, German OCR,…). So we recommend that you try engine1 first (since it is faster!), but if the OCR results are not perfect for your use case, please try the same document with engine2. You can use the new OCR engine with our free online OCR service on the front page, and with the OCR API.
To test the new OCR engine right away, use the free online OCR feature on our front page. You can switch between both OCR engines and compare the result.
Key Features of the new OCR Engine2
• Western Latin Character languages (English, Spanish, Portugese,…)
• Language auto-detect (so it does not really matter what OCR language you select, as long as it uses Latin characters)
• Usually better at single number OCR and alphanumeric OCR (e. g. SUDOKO,Dot Matrix OCR, MRZ OCR,… )
• Usually better at special characters OCR like @+-…
• Parameter: OCREngine=2
• No PDF OCR and Searchable PDF creation yet. If you need this, please contact us for an internal beta.
• Not available as Offline OCR yet. If you need this, please contact us for an internal beta.
Key Features of the default OCR Engine1
• Supports more languages (e.g. Arabic, Russian, and many Asian languages like Chinese, Japanese and Korean)
• Faster
• Parameter: OCREngine=1
The format of returned OCR API result (JSON) is identical for both engines. Thus you can easily switch between both engines as needed. If you have any question about using Engine 1 or 2, please ask in our UI.Vision OCR API Forum.
For more detailed information about the PROs and CONs of each engine, please see the new OCR Engine section in the API documentation.
Example OCR Test Cases
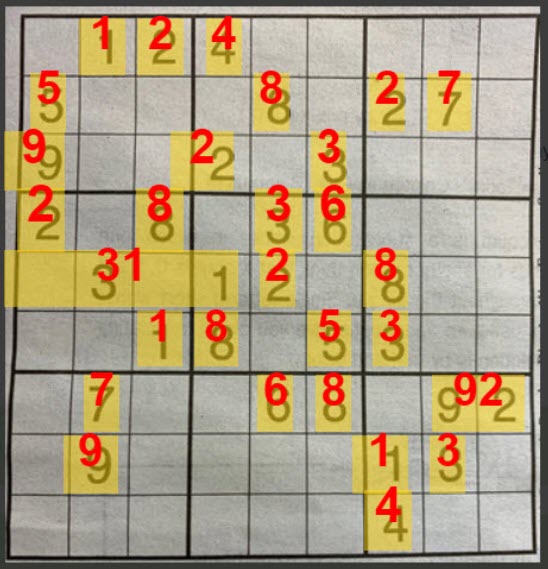
Sudoko Number OCR
The SUDOKO test case is directly from the OCR Forum. Engine1 does not find any of the single digit numbers, but Engine2 works well:
Get values from Measurements
Again, this test case is a user submitted test image. Here engine1 performs OK, but engine 2 is better:

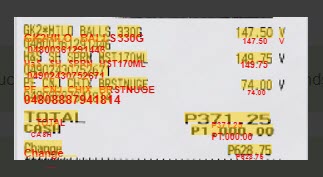
Receipt OCR
In general Engine2 is usually somewhat more accurate for receipt OCR. But it depends on your use case (input images) which engine works better for receipts and invoices. Please try it out.
Screenshot OCR, Screen Scraping
For OCRing screenshots, both OCR engines deliver usually a very good result. We use the OCR API as part of the UI.Vision RPA screen scraping support.
PRO OCR API support
Please note that Engine 2 is not yet available on the PRO OCR API high-performance servers. As always, the free OCR API gets the update first. We know that our PRO OCR API customers value stability and reliability above new features, so the PRO OCR API endpoints will get this update a few weeks later, once we are 100% sure everything runs rock-stable.
If you have a PRO or PRO PDF plan subscription and want to use the new features right away, you can already do so by connecting to free API endpoint at https://api.ocr.space/parse/image . This way you can start testing the new OCR engine right away. If you use your PRO API key to connect to the free API, you do not have any of the free OCR API limits.