Best Online OCR Software for Chinese Characters - Review

Update May 1, 2015: (a9t9) launched its very own free and open-source Online OCR service - try it out and let us know how it compares.
Think English language OCR is hard? Then try Chinese. This is what I did for this review. When I reviewed Online OCR services for English, there were 5 OCR surprises. Now I am back, looking at OCR software for Chinese characters.
Why is Chinese OCR difficult?
Why is Chinese OCR more difficult than, say, English or German document OCR?
Optical character recognition by itself is still hard. It is not a solved problem, at least not for the software available to end-users. The result of our English OCR benchmark have been mixed. But Chinese language OCR takes the challenge to another level. Here is why:
(1) Number of characters: A typical Western alphabet has around 24-30 characters whereas Chinese OCR software has to learn far more that that. To be useful, it needs to know at least the 6,763 simplified Chinese characters the GB–2312 standard. Then add another ~5000 or so traditional versions of characters to the mix. So we have at least 10,000 characters. This also means: Some rare characters may not be recognized simply because they’re not in the database – something that cannot happen in English.
(2) Every new character the software supports is another character that might potentially result in a false positive match, so there is a limit for the sake of accuracy.
(3) In Chinese, a character (or two) resembles an English word. Example: 手机 = Mobile Phone (literally: hand machine). In this example 2 Chinese characters = 11 English characters. So the information density in Chinese texts is much higher. This also means the text size needs to be greater. Typical lower limits for OCR software are 15 pixels for Western languages or 20 pixels for East Asian languages.
OCR Software Benchmark for Chinese
For this review a Chinese OCR benchmark consisting of of six images was created: A document scan of magazine article in three different qualities (300dpi, 100dpi, 75 dpi), a Lumia 535 smartphone image of the article, and screenshot of two movie subtitles (more about the movie subtitles later).
1. High-Quality Chinese Scan (300 dpi)
Test 1: Chinese OCR, 300dpi 
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abby Finereader | 100% | 在中国,餐厅里的菜通常很特别, |
| Google Docs OCR | 100% | 在中國,餐斤里的菜通常很特別, |
| OnlineOCR | 100% | 在中国,餐厅里的菜通常很特别, |
| i2 OCR | Good | 在中国, 餐厅里的菜通常壕艮特另u, |
| NewOCR | 100% | 在中国, 餐厅里的菜通常很特别, |
The first test uses a high-quality scan of a magazine article. All services that can recognize Chinese characters did well in this test, most with no error (100%) and some with almost no error (good).
Having said that, some services that I reviewed for English language OCR do not support Chinese and are thus not part of this review.
1. Low-Quality Chinese Scan (100 dpi)
Test 2: Chinese OCR, 100dpi Scan 
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abby Finereader | Good | 在中“,枝厅里的芡通常很持别 |
| Google Docs OCR | Good | 在中山,餐訂里的菜通常很特別, |
| OnlineOCR | Good | 在中囚,各厅里的菜通常很特别 |
| i2 OCR | Fail | 在中山l 鲁汀里的菜通常很牺易ul, |
| NewOCR | Poor | 在中凹. 稷汀呈的菜逆常很持别l |
The 100 dpi scan the text is easily readable for a human, even so it is somewhat blurred. For OCR systems this resolutions is close to limit of the technology can handle. Three competitors barely got the good grade, while one service is unusable.
3. Very low-Quality Chinese Scan (75 dpi)
Test 3: Chinese OCR, 75dpi Scan [ ]
]
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abby Finereader | Fail | (no text) |
| Google Docs OCR | Fail | (no text) |
| OnlineOCR | Fail | 往中工肠泞王的共诵常很特别 |
| i2 OCR | Fail | 仕申重. g厅虫的翼矗薰蟹麟颤」, |
| NewOCR | Fail | 仨中重. 器焘虫的翼邃篱氰麝蒽上 |
Humans can still read this text, even so it involves guessing a few characters from the context. Not so our PC – every single OCR software flunked this test.
4. Smartphone image
Test 4: Smartphone camera 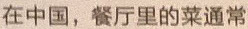
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abby Finereader | Good | 在中国,说厅里的菜通常很特別, |
| Google Docs OCR | Fail | OCR not trigged |
| OnlineOCR | Good | 在中国,偿厅里的菜通常很特别, |
| i2 OCR | Fail | 在口口五, 餐厅里的粟遇常抒艮持另u, |
| NewOCR | Good | 在中国, 餐厅里的菜通常很特别, |
Using your mobile phone as scanner? Sure, that works. Three services deliver a good conversion result despite the yellowish background and somewhat oblique text. Surprisingly Google OCR fails this test: Google Docs no longer has a dedicated “Start OCR” button and the automatic OCR fails to trigger.
5/6: Chinese movie subtitles
This is not your average OCR task. The challenge here are the backgrounds. Of-the-shelf OCR systems have a very hard time distinguishing text from the background.
Test 5: Movie Subtitle 1 
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abby Finereader | Poor | 1 ^跳,彳II见上面的字吗 |
| Google Docs OCR | Poor | 行得現上面的字 |
| OnlineOCR | Fail | ).ir-iv一目日口 |
| i2 OCR | Fail | (no text) |
| NewOCR | Poor | 唰 得见上面的学吗 |
In Subtitle 1 (from the movie Anchoring Seattle, not that this matters….) the subtitle is white on green. No OCR software can read it ok. But Abbyy, Finereader, Google OCR and NewOCR detect at least a few characters correctly.
Test 6: Movie Subtitle 2 
| OCR Service | Result | Output (Excerpt) |
|---|---|---|
| Abby Finereader | Fail | (no text) |
| Google Docs OCR | Fail | (no text) |
| OnlineOCR | Fail | .叫口圈团口睡鼠喻戒… |
| i2 OCR | Fail | (no text) |
| NewOCR | Fail | 莪问大z 之… > .二_… |
In Subtitle 2 (from the movie Good for Nothing Heroes) we have a street scene and the subtitle is white on a greyish background. No OCR software can read the characters, despite the large size characters (screenshot from full-screen Youtube replay of the Chinese movie).

In my February OCR review, Abbyy OCR did a great job reading numbers from a gas meter image, so I am surprised it does not better here. But I used Abby FineReader instead of the Abbyy Cloud SDK for this review, as it is easier to use and showed no significant difference in recognition rates in a pre-test. So I went back to the cloud SDK for the subtitle recognition. And indeed, Abbyy Cloud SDK seems to have a more powerful recognition engine and/or background removal. It recognized Subtitle 1 and 2 at least partly. I would love to know why all OCR services miss the ~ first half of both subtitles completely.
Summary - Best OCR (web) software for Chinese characters
| Ranking | Score | Scan1 | Scan2 | Scan3 | Mobile | Sub1 | Sub1 |
|---|---|---|---|---|---|---|---|
| Abbyy FineReader | 8 | ++ | + | - | + | 0 | - |
| OnlineOCR | 7 | ++ | + | - | + | - | - |
| Google Docs OCR | 6 | ++ | + | - | - | 0 | - |
| NewOCR | 6 | ++ | 0 | - | + | 0 | - |
| i2 OCR | 2 | + | - | - | - | - | - |
Just like with English Google OCR disappoints and is clumsy to use. It seems to be some kind of black magic if or if not the OCR conversion is triggered. If it fails, no error messages guides the user. And if it works, it works just average. The TOP 3 spots are exactly the same as in the English language OCR test: Abbyy wins the review, and the “no-name” OnlineOCR service comes in second - and is the best free OCR service. Google ranks only 3rd, along with NewOCR. So the surprise of this OCR for Chinese characters review is: No surprises - or in other words: We learned that whatever OCR software did well for English also did well for Chinese.
Chinese language version of this article: 最棒的在线中文OCR软件-评介
References
Reviewed online OCR services:
- Abbyy OCR SDK/API
- OnlineOCR
- Google Docs OCR
- i2OCR
- FreeOnlineOCR
- Tesseract Online Demo (flunked even the 300 dpi OCR test)
OCR benchmark - test images:
- Chinese magazine scan, 300 dpi
- Chinese magazine scan, 100 dpi
- Chinese magazine scan, 75 dpi
- Chinese magazine smartphone “scan”
- Chinese movie subtitle 1 (green background)
- Chinese movie subtitle 2 (grey background)
- All test images are available on GitHub: OCR Benchmark
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}