
Table Recognition with OCR
How to extract data from tables inside a scanned PDF or image
One of the many use cases of OCR is to extract data from images of tables - like the one you find in a scanned PDF. Other
document types like receipts, invoices, contracts and more also follow the same layout and also benefit from our table OCR feature. For all these documents we recommend
that you enable check the Receipt scanning and/or table recognition option on the front page. If you use the OCR API, you get the same result
by turning on the table OCR mode.
The result is that the OCR'ed text is sorted line by line - just like you find it in the table.
This makes the OCR API the perfect receipt capture SDK.
Table Parsing Example
The screenshot below shows the OCR result of an image of a table scan, in this case from a Chinese text book. With the table OCR mode active, the structure of the text output is the same as on in the table.
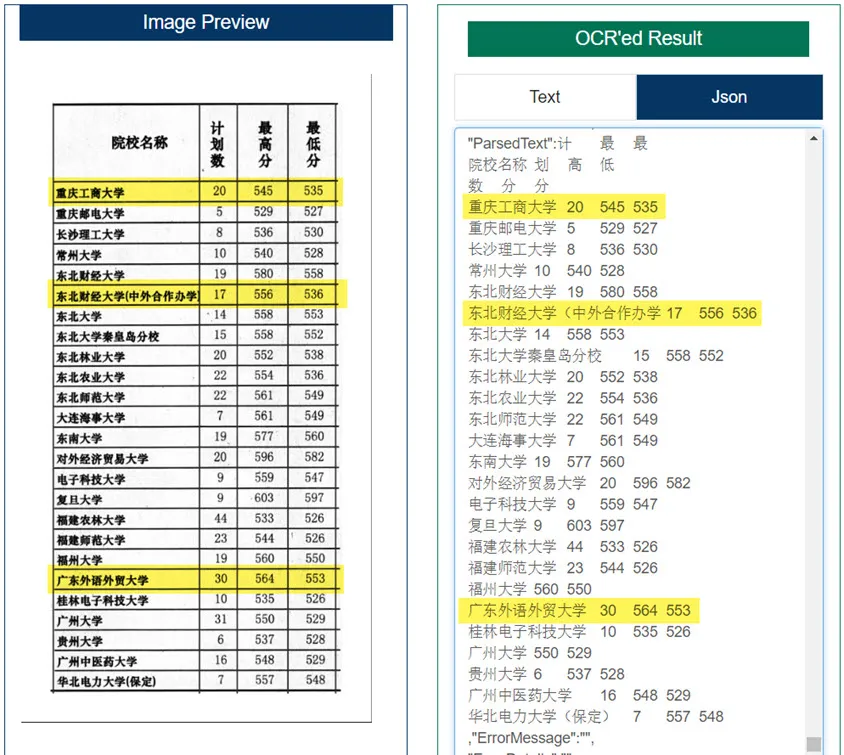 We highlighted a few lines in yellow to visually help you to compare the left input image and the extracted OCR
table data on the right.
We highlighted a few lines in yellow to visually help you to compare the left input image and the extracted OCR
table data on the right.
Table OCR API
In the OCR API the isTable = true switch triggers the table scanning logic.
More details are available in the table OCR flag section
of the OCR API documentation
Test Table OCR
You can test table parsing and data extraction directly on our front page. Here is the original table textbook scan. In this case the selected OCR language is Chinese:
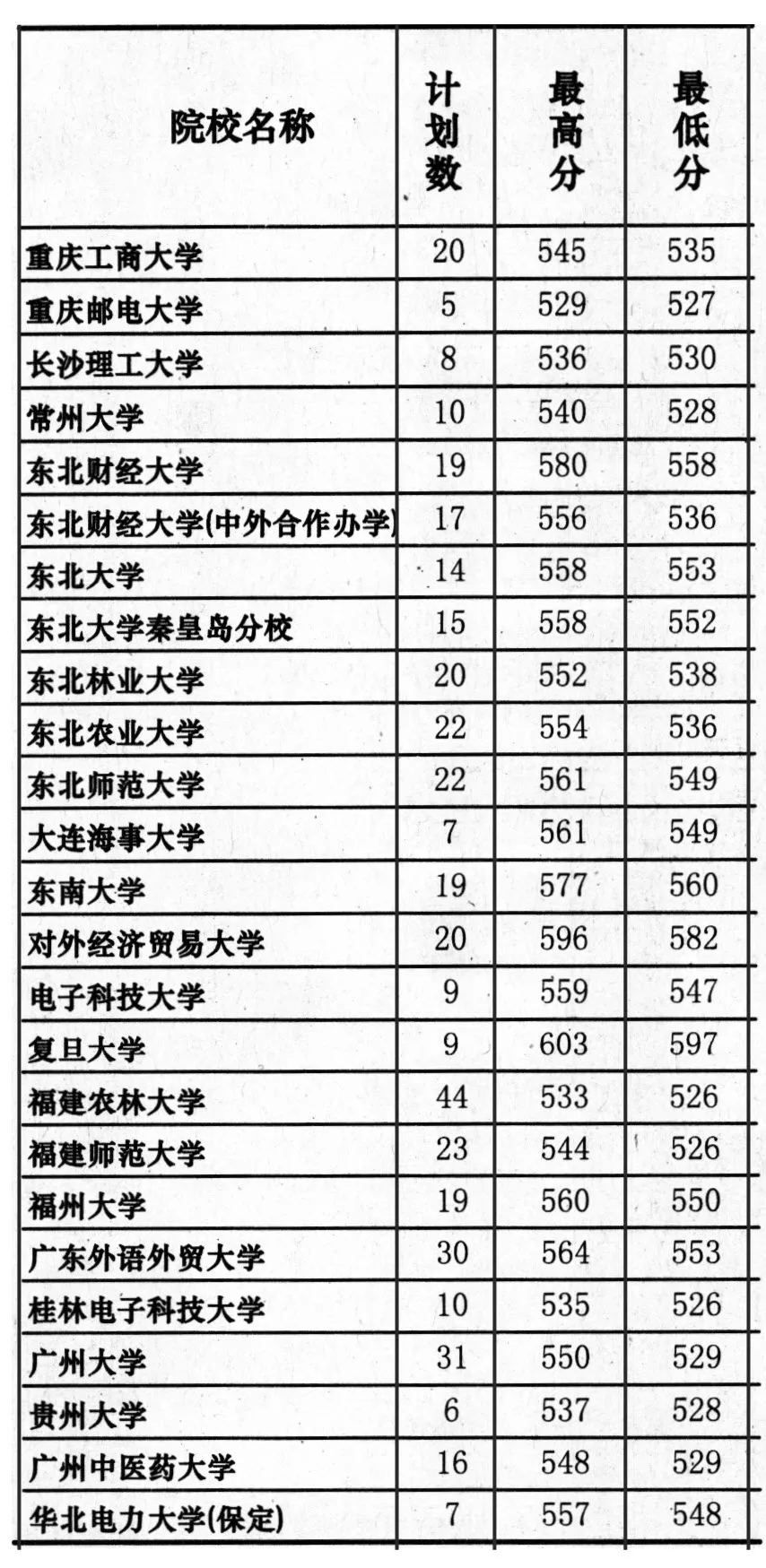 The link to the table image is
The link to the table image is https://ocr.space/content/images/table-ocr-original.jpg
- just paste it into the URL box on the front page.
Table to Markdown
Another option for table ocr is OCR engine 3. It directly converts tabular data to the standard markdown table format